

KNIME: Data Science sin programación
ETL completo con KNIME
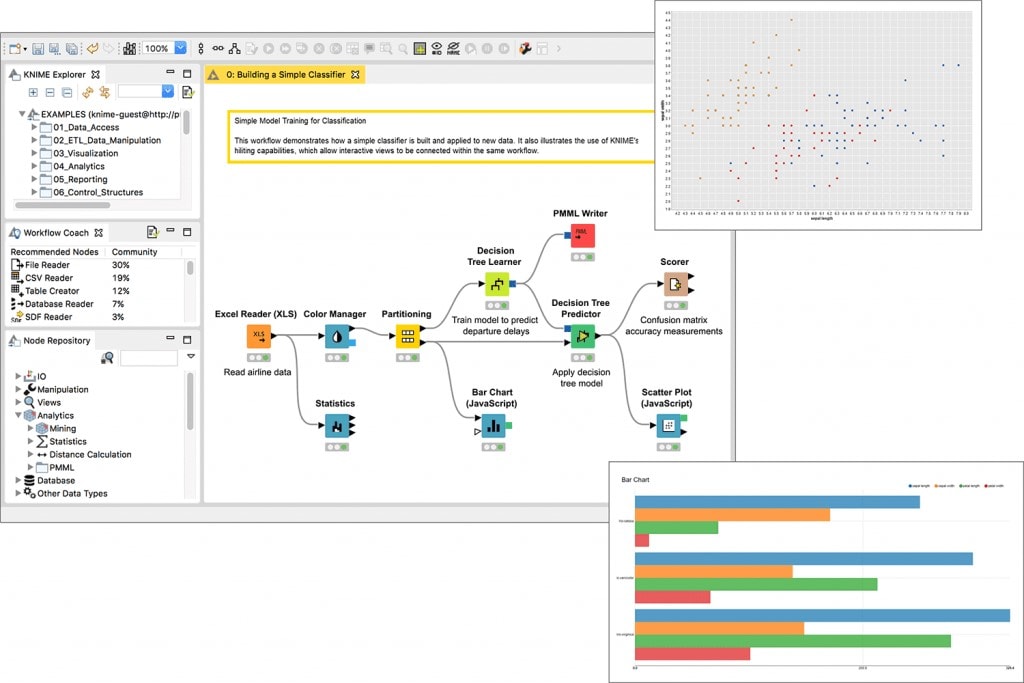
Ya os hemos hablado en alguna otra ocasión de KNIME, una herramienta que nos ayuda a crear plataformas de Data Science de manera sencilla e intuitiva, mediante el trabajo con flujos de datos ETL (Extract, Transform and Load), estructurados en tablas (filas y columnas). Es capaz de hacer de una tecnología compleja como el Big Data, algo entendible y manejable para cualquier perfil de empresa.
Los adjetivos ‘sencilla’ e ‘intuitiva’ que anunciábamos en las primeras líneas de esta entrada, nos los hemos elegido al azar, ya que las potencialidades de uso de esta herramienta van más allá de los procesos de pura gestión del dato que veremos más adelante. Al basarse en GUI (Graphical User Interface o Interfaz Gráfica de Usuario), KNIME ofrece un interfaz gráfico natural, que permite trabajar en entornos Data Mining sin conocimientos de programación.
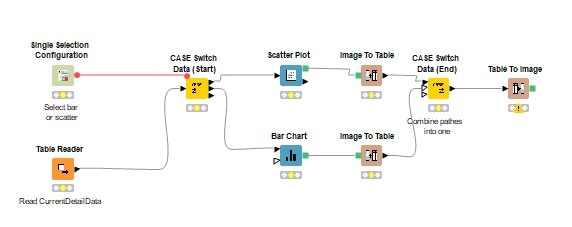
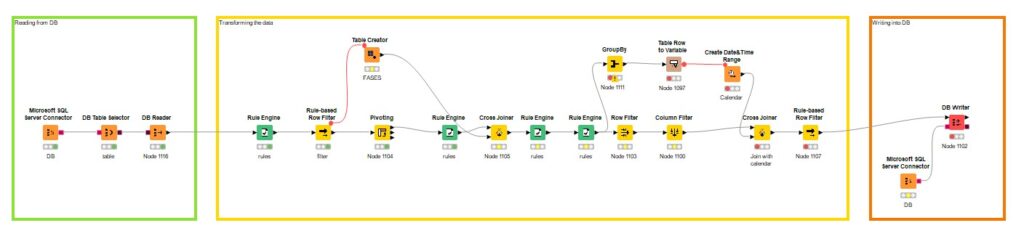
En este sentido, las estrellas de KNIME son los nodos, visualmente representados por ‘cajitas’ por las que pasan los datos para aplicarles las acciones deseadas. Cada nodo realiza una operación sobre nuestros datos, logrando un flujo completo con nodos interconectados (figuras 1, 2 y 3). Una de las grandes ventajas de este modo de trabajo frente a las líneas de código, es que podemos ir viendo los pasos intermedios que damos en cada transformación en un solo vistazo.
Además, KNIME pone a disposición de los usuarios un montón de documentación detallada de cada uno de los nodos, e incorpora ejemplos de flujos para ilustrar dicha la información.
ETL completo con KNIME
Volviendo a sus potencialidades en la gestión del dato, la herramienta que estamos analizando,posibilita elaborar, como ya hemos reseñado, un flujo completo de ETL. Veamos las opciones que nos da:
- Conexión a fuentes de datos de todo tipo: Bases de Datos como Oracle, Microsoft SQL o incluso Azure, archivos de texto como Excel, CSV, JSON, etc.
- Tratamiento de los datos extraídos: Knime permite hacer todo tipo de modificaciones en nuestros datos, desde filtrar filas y columnas, unir información procedente de distintas tablas, hacer operaciones entre columnas o incluso agrupaciones de filas. De este modo, podemos depurar los datos y dejarlos listos para cargarlos en la misma u otra fuente de destino.
- Además del tratamiento y transformación de los datos, KNIME también permite aplicar técnicas de analítica avanzada sobre los mismos, para extraer todo tipo de estadísticas de esos datos.
- Por otro lado, podemos ir un paso más allá generando modelos de Machine y Deep Learning, como árboles de decisión, o incluso redes neuronales, a partir de un conjunto de datos de entrenamiento, y realizar predicciones sobre un conjunto de test.
- Se puede evaluar la precisión de los modelos creados mediante técnicas de scoring.
- Se pueden obtener gráficos que muestren los resultados obtenidos.
- Los datos finales pueden cargarse de nuevo a una Base de Datos, o pueden escribirse en ficheros de texto tipo CSV.
- Los desarrollos creados a partir de KNIME pueden compartirse, de modo que pueden ser reutilizados por otro usuario.
- También se pueden poner en producción, es decir, el flujo puede exportarse y ejecutarse de forma automática periódicamente, de modo que podemos alimentar una base de datos con resultados periódicos.
Como vemos, KNIME es una herramienta, intuitiva y sencilla, con un enorme potencial por su fácil de integración y escalabilidad; por su sencillez de cara a articular complejos flujos de datos de los que extraer conocimientos valiosos; por su capacidad para articular modelos de Machine Learning en apenas un par de clicks, por la importante red de apoyo que aporta el propio software y la comunidad creada en torno al mismo, por su rápida curva de aprendizaje… en definitiva, por su capacidad de hacer fácil lo difícil.
Conclusión
Como conclusión podríamos decir que KNIME Analytics Platform es una herramienta Open Source y User Friendly que permite el desarrollo de flujos de transformación de datos (ETL) de una forma sencilla, sin necesidad de programar. En este sentido, una de sus principales potencialidades es que cuentan con una gran variedad de nodos con los que llevar a cabo desde la carga y transformación de datos, hasta el desarrollo de modelos de Machine Learning y su posterior carga a un repositorio. Además, como ventaja frente a las líneas de código, posibilita comprobar el estado intermedio de los datos a medida que se realizan transformaciones, sin que estos cambios sean efectivos en la Base de Datos hasta que se escriben en ella.
 Contactar
Contactar