

Deep Learning, redes neuronales y visión artificial
Redes Neuronales Convolucionales

El aprendizaje es una condición inherente al ser humano. Desde que nacemos recopilamos información y la almacenamos para poder realizar las tareas que nos requiere el día a día. Este proceso tan nuestro, de los seguramente mal llamados animales racionales, ya no nos es exclusivo. Las máquinas son capaces de aprender o, mejor dicho, somos capaces de hacerlas aprender.
Gracias al desarrollo de la Inteligencia Artificial (AI) hemos logrado que los ordenadores imiten determinadas funciones propias los humanos. Pero esto no queda aquí, como ya hemos apuntado, un paso más, y no uno cualquiera, sino uno cuantitativo, se ha dado al conseguir no solo que las máquinas ejecuten acciones, si no que las aprendan y mejoren su propio desempeño.
Este proceso autoeducativo se consigue mediante la implementación de sistemas de Machine Learning o aprendizaje automático, una rama de la IA orientada al desarrollo de algoritmos que imitan las funciones cognitivas humanas. A su vez, dentro de esta técnica, se ha desarrollado el Deep Learning que trabaja con el concepto de malla, generando redes neuronales artificiales que simulan el funcionamiento de las redes neuronales biológicas y, en consecuencia, el proceder del complejo cerebro humano.
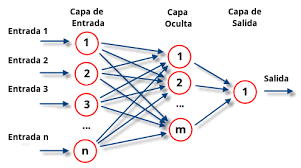
Como su propio nombre indica, el Deep Learning (aprendizaje profundo), deriva de la utilización de capas ocultas en la composición de las redes neuronales. Estas cuentan con una capa o fuente de entrada de datos que nutre al conjunto, multitud de capas intermedias de las que no conocemos los valores tratados, y una capa de salida que muestra el resultado del procesamiento de datos efectuado por la red. Siguiendo con el paralelismo hombre-máquina, el procedimiento digital mencionado responde a un itinerario similar al que se produce si, por ejemplo, nos tiran un balón: nuestros ojos captan la imagen de un objeto en movimiento (fuente de entrada), el cerebro procesa la información recibida: tamaño, velocidad, peso estimado, color, material… (capas ocultas), y con esos datos tratados damos una respuesta al estímulo inicial (capa de salida).
Dentro de las múltiples potencialidades de este complejo y completo sistema, el Deep Learning destaca en los procesos de análisis, reconocimiento y clasificación de imágenes, a partir de un modelo entrenado (visión artificial). Cualidad cada vez más útil si tenemos en cuenta que la información gráfica se ha universalizado gracias al abaratamiento y extensión de la tecnología. Hoy en día podemos disponer de un gran abanico de tomas, muchas de ellas en tiempo real, captadas por cámaras (fijas o móviles, terrestres o aéreas), ultrasonidos, radiofrecuencia o satélites, lo que posibilita innumerables usos en campos muy diversos como el mantenimiento de instalaciones, la conducción automática de vehículos, la optimización de flotas y almacenes, el diagnóstico médico, o el análisis de superficies (cultivos, catástrofes, ingeniería…), entre otras muchas.
Redes Neuronales Convolucionales
En el desarrollo de la capacidad de las computadoras de ‘ver’, ya sea determinando que representa una imagen en su conjunto (clasificación) o detectando un objeto que forme parte de ella (control del uso de la mascarilla en la crisis del COVID que estamos viviendo, por ejemplo), están especialmente indicadas las Redes Neuronales Convolucionales CNN (Convolutional Neural Networks) ya que, a diferencia de las redes neuronales convencionales y otros algoritmos de clasificación de imágenes, procesan la información de manera rápida y sencilla.
Su sistema de trabajo se basa en la localización de patrones en áreas reducidas de la imagen y no en su conjunto. Para ello, el algoritmo toma un pequeño cuadrado de pixeles (entrada) que pasarán por diversas capas ocultas organizadas para una ejecución analítica gradual, es decir, las primeras capas de la red detectarán características simples líneas, curvas, bordes… siendo las capas más profundas capaces de reconocer formas complejas como personas, vehículos o animales. En consecuencia, a mayor número de capas mejor será la ‘capacidad de visionado de la red’, y más certera la su salida, que nos muestra como resultado del análisis la probabilidad de que una imagen pertenezca a una categoría preestablecida, que la red está entrenada para reconocer.
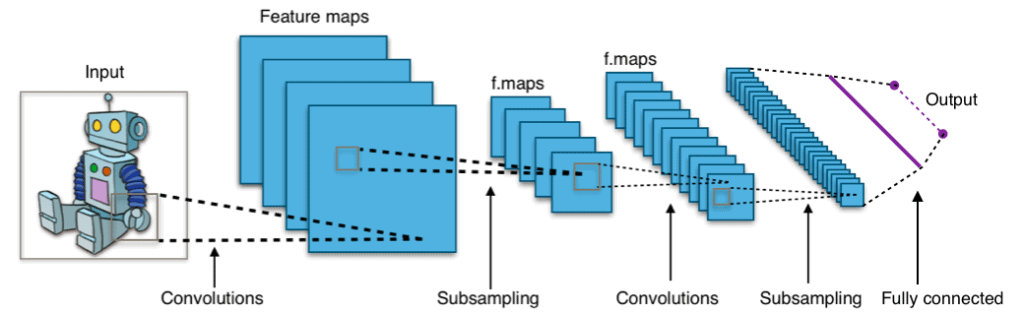
Lo más interesante de todo el proceso es que, en cada capa, la red interconecta las distintas características de la imagen usando esa información para aprender y mejorar su capacidad de reconocimiento, llegando, como hemos mencionado, a identificar formas de alta complejidad en los últimos pasos. Partiendo de este autoabastecimiento, se puede conseguir un mecanismo autónomo entrenando a la red neuronal con un amplio espectro de imágenes que utilizará para generar su propia memoria. Pasada esta fase, el modelo de Deep Learning estará listo para enfrentarse a nuevas imágenes exentas de clasificación previa.
De la teoría a la práctica
Como ya hemos apuntado la visión artificial o visión computacional tiene innumerables aplicaciones que, además, aumentan día a día, al ritmo que lo hace el desarrollo de las nuevas tecnologías de captación de imágenes. Para trasladar al campo práctico la teoría, vamos a exponer ejemplos de trabajos que hemos realizado en LIS Solutions en el marco del Deep Learning aplicado a soluciones visuales.
LOCALIZACIÓN DE INSTALACIONES
Una operadora logística internacional nos planteó la necesidad de localizar las mejores ubicaciones e instalaciones en radios territoriales determinados, con el fin de adquirir almacenes cercanos a sus áreas de distribución masiva. Conocida la demanda desarrollamos una solución de búsqueda, con algoritmos de cuadraticidad, a través de imágenes satelitales, que relacionamos con datos catastrales para la identificación de parcelas y edificios, y su clasificación en función de su potencialidad de compra según la conjunción de parámetros como tamaño, geometría, simetría, localización y precio por m2. Creamos, además, una red neuronal convolucional que fue capaz de clasificar las imágenes según el tipo de suelo y el tipo de edificación.
SEGMENTACIÓN AUTOMÁTICA DE TUMORES
Un reto completamente diferente, pero también resuelto con Deep Learning, fue el que nos plantearon desde una entidad académica para implementar algoritmos que pudieran realizar una segmentación automática de tumores en imágenes de resonancia magnética, con el objetivo de agilizar los procesos de identificación primaria y toma de decisiones.
Y manos a la obra. En este caso diseñamos un modelo de segmentación automática de gliomas de alto grado, HGG, cuya arquitectura se basa en el empleo de redes neuronales convolucionales simétricas. Los resultados en cuanto a la obtención de mapas binarios de segmentación de los tumores fueron muy positivos, con un buen desempeño a la hora de localizarlos espacialmente.
MANTENIMIENTO DE GRANDES INFRAESTRUCTURAS
En estos momentos, uno de los proyectos en los que estamos inmersos, está orientado solucionar los problemas de vigilancia y mantenimiento de una gran infraestructura industrial. A través de imágenes tanto satelitales como obtenidas por cámaras estamos generando un sistema de detección precoz de anomalías que pueden ser el resultado de roturas y averías o derivar en ellas.
En este caso las redes neuronales están entrenadas para localizar e identificar formas y objetos espontáneos en las imágenes tomadas. Dicho de otra manera, el algoritmo detectará todo aquello que esté en un lugar en el que no tenga que estar, como ejemplos pueden servirnos elementos como fuego o fugas de producto.
DETECCIÓN DE PLAZAS DE APARCAMIENTO
Llevando las potencialidades del tratamiento gráfico con Deep Learning al terreno cotidiano, una aplicación que puede tener la visión computacional es la detección de espacios de aparcamiento. Esta tarea puede ser muy útil en la calle, pero lo es más aún en instalaciones dedicadas al almacenaje de vehículos, como puede ser un puerto. En estas infraestructuras, diferentes actores operan simultáneamente con diferentes volúmenes y rotación de unidades, por lo que sería especialmente provechoso conocer de antemano que plazas están vacantes en cada momento, cuándo se necesita más espacios, o qué áreas resultan más adecuadas para un uso determinado.
En este caso, a través de un algoritmo de visión artificial, identificaríamos en la imagen los espacios y, posteriormente, por medio de un clasificador, determinaríamos la presencia o ausencia de un vehículo.
 Contactar
Contactar