

Predicción de la demanda
Objetivos
Con el análisis de datos de diversas fuentes y el uso de algoritmos de Machine Learning el sistema es capaz de automatizar la previsión de la demanda y con ello optimizar las operaciones de aprovisionamiento y compras así como la mejora de procesos productivos.
Objetivos
- Realizar predicciones que aportan información sobre el futuro a nivel operativo
- Aportar una herramienta de ayuda en la toma de decisiones a nivel dirección
- Proporcionar conocimiento del negocio durante la etapa de análisis
Conocer la demanda de un producto/servicio ha sido siempre un factor muy importante en todos los negocios, desde negocios de barrio a grandes empresas logísticas, eléctricas, etc. La transición de la toma de decisiones empresariales basadas en «»corazonadas»» fue sustituida por el análisis de datos realizado en hojas de cálculo, y ya ha sido superada mediante la implementación de algoritmos de «»Machine Learning»», que son capaces de automatizar y realizar a gran escala todos estos cálculos.
Qué hacemos
Tras conocer en detalle el negocio y las peculiaridades de sus datos, realizamos análisis exploratorios con el fin de determinar qué algoritmos y con qué configuraciones son adecuados. Utilizando tanto métodos univariables o multivariables podemos predecir series temporales de consumos, producciones o gastos. Estos se integran en procesos ETL y se seleccionan los algoritmos que producen los mejores resultados en un proceso iterativo que puede automatizarse mediante reglas heurísticas.
Cómo lo hacemos
Análisis exploratorio
Analizamos la calidad del dato y representamos la información de múltiples formas (lineas-puntos, histogramas, box plots) con el objetivo de identificar aquello de mayor valor, corroborándolo con el conocimiento de negocio del cliente.
Esta etapa se realiza mediante la librería pandas de Python
Selección de algoritmos
Disponemos de algoritmos (Naive, SNaive, HoltsWinter, STLF, Forecast, VAR, Prophet) implementados o implementamos nuevos en caso ser necesario ( por ejemplo, redes neuronales del tipo LSTM). Se procede a la validación de los algoritmos utilizando métricas de error para seleccionar el más adecuado.
Explotación de los datos
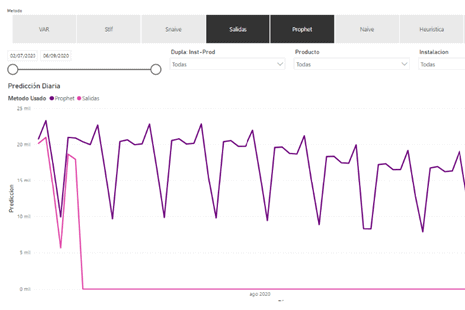
Realizamos un cuadro de mando para visualizar los resultados, configurado y adecuado a las necesidades y exigencias del cliente, permitiéndole tomar decisiones Data Driven.
En caso de ser necesario, se implementan también las reglas de heurística empleadas para la reselección de algoritmos/configuraciones.
 Contactar
Contactar