

Web Scraping Medicamentos
Objetivos

Utilizando herramientas de web scrapping y RPA se extraen precios de medicamentos de sitios web. Estos datos se unen a información de fuentes open data, alimentando un dataware house que contiene series temporales de los precios y su evolución en el tiempo.
Objetivos
- Extraer los precios de los medicamentos de diferentes orígenes
- Generar un datawarehouse con series temporales de precios de medicamentos
- Generar una herramienta de consulta de precios
Los precios de los medicamentos y material sanitario en el entorno de la Unión Europea están fuertemente regulados, siendo los gobiernos de cada país, o incluso cada región, los que fijan sus precios de acuerdo con la situación socio-económica y su clasificación en genéricos, únicos o no subvencionados. Los datos publicados por los países suelen estar en formatos difíciles de tratar, principalmente pdf.
Qué hacemos
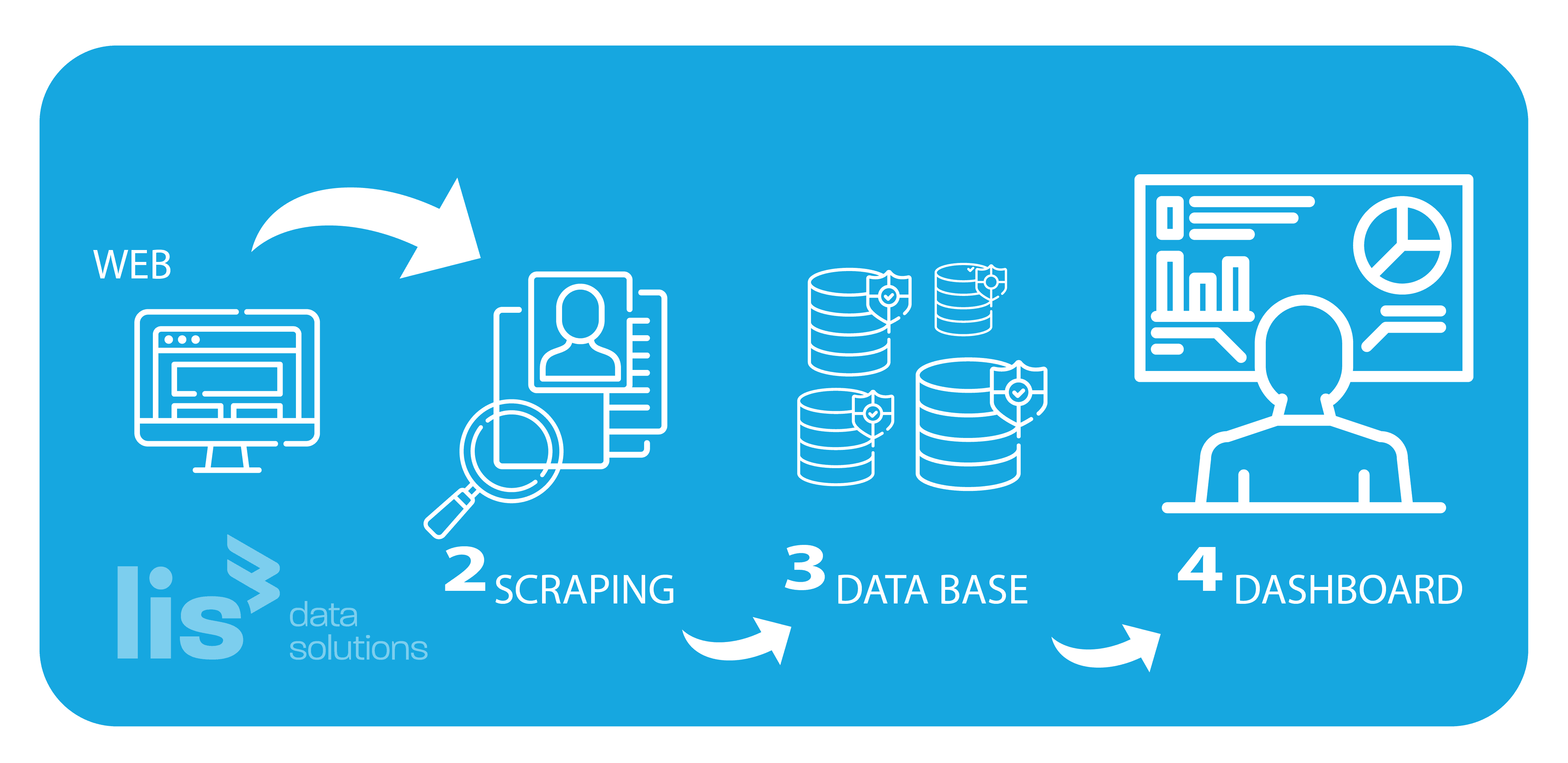
Generamos un dataset potente para poder realizar, en fases posteriores, estudios avanzados sobre los datos. Por ello, en esta primera fase nos centramos en la obtención y generación del almacén de datos, conectándonos a datos publicados por organismos públicos y privados, empleando en algunos casos tecnologías de RPA (Robotic Process Automation) y web scrapping que nos permitan extraer información de casi cualquier documento o web site.
Cómo lo hacemos
Catálogo y clasificación.
La primera fase consiste en el diseño del modelo de datos que contendrá el catálogo de referencias, países y clasificación.
Destaca la importancia de la información de la que se dispondrá, así como el volumen de datos que se podrá extraer.
Extracción.
Diseñamos y desarrollamos los web scraper y procesos robotizados de extracción de precios para cada uno de los orígenes identificados, así como para los portales de salud de cada país.
Implementamos un datawarehouse y modelo de datos para el almacenamiento de todas las series temporales identificadas.
Almacenamiento y visualización.
Adaptamos los datos al modelo mediante procesos ETL, concluyendo el proceso con el almacenamiento en el repositorio de datos implementado.
Desarrollamos y desplegamos los cuadros de mando, informes e indicadores KPI que facilitan la consulta y exploración de la información.
 Contactar
Contactar