

KNIME: Data Science ohne Programmierung
Vollständige ETL mit KNIME
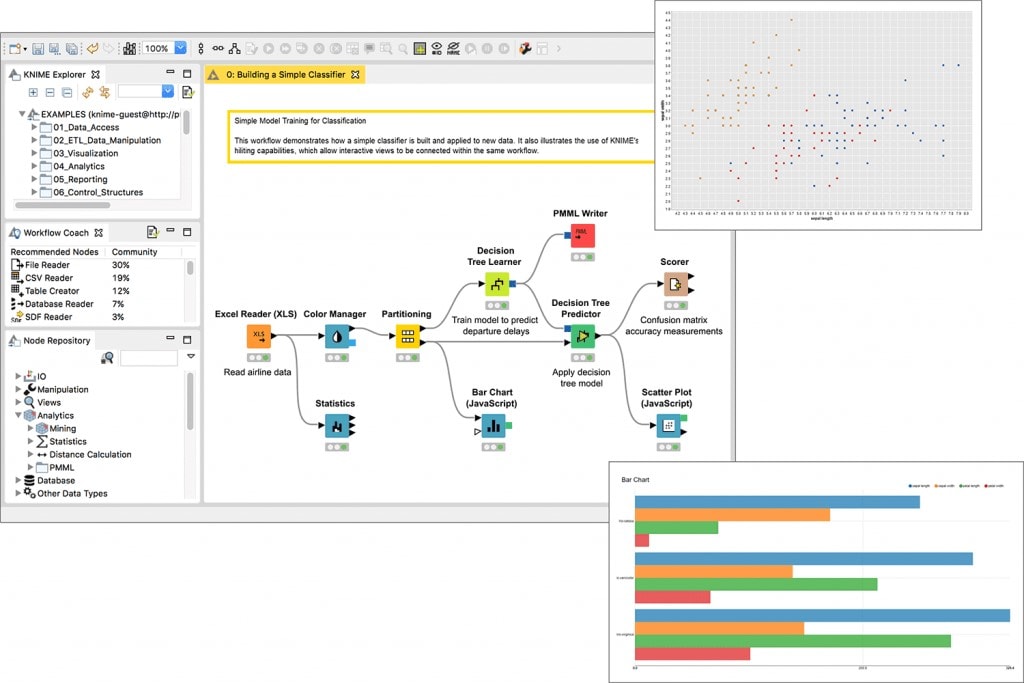
Wir haben bereits über KNIME gesprochen, ein Tool, das uns hilft, Data Science-Plattformen auf einfache und intuitive Weise zu erstellen. Dazu arbeitet es mit ETL-Datenströmen (Extract, Transform and Load), die in Tabellen (Zeilen und Spalten) strukturiert sind. Sie ist in der Lage, eine komplexe Technologie wie Big Data, für jedes Unternehmensprofil verständlich und handhabbar zu machen.
Die Adjektive „einfach“ und „intuitiv“, die wir in den ersten Zeilen dieses Eintrags angekündigt haben, haben wir nicht zufällig gewählt. Das das Nutzungspotenzial dieses Tools geht über die Prozesse der reinen Datenverwaltung hinaus, wie wir später sehen werden. Da KNIME auf GUI (Graphical User Interface) basiert, bietet es eine natürliche grafische Oberfläche Dies ermöglicht das Arbeiten in Data-Mining-Umgebungen ohne Programmierkenntnisse.
In diesem Sinne sind die Sterne von KNIME die Knoten, visuell dargestellt durch „Kästchen“, durch die die Daten laufen, um die gewünschten Aktionen anzuwenden. Jeder Knoten führt eine Operation an unseren Daten durch, wodurch ein vollständiger Fluss mit miteinander verbundenen Knoten entsteht. Einer der großen Vorteile dieser Arbeitsweise im Vergleich zu Codezeilen ist, dass wir die Zwischenschritte, auf einen Blick sehen können.
Darüber hinaus stellt KNIME dem Anwender eine ausführliche Dokumentation für jeden der Knoten zur Verfügung. Die Dokumentation enthält Beispiele von Abläufen zur Veranschaulichung der Informationen.
Vollständige ETL mit KNIME
Um auf sein Potenzial im Datenmanagement zurückzukommen: Das von uns analysierte Tool ermöglicht es, wie bereits skizziert, einen kompletten ETL-Fluss auszuarbeiten. Schauen wir uns die Optionen an, die es uns gibt:
Anbindung an Datenquellen aller Art: Datenbanken wie Oracle, Microsoft SQL oder auch Azure, Textdateien wie Excel, CSV, JSON, etc.
Behandlung der extrahierten Daten: Knime erlaubt uns, alle Arten von Modifikationen an unseren Daten vorzunehmen. Dies reicht vom Filtern der Zeilen und Spalten über das Verbinden von Informationen aus verschiedenen Tabellen. Selbst Operationen zwischen Spalten oder sogar dem Gruppieren von Zeilen ist möglich. Auf diese Weise können wir die Daten debuggen und sie zum Laden in dieselbe oder eine andere Zielquelle bereitstellen.
Neben der Datenverarbeitung und -transformation ermöglicht KNIME auch die Anwendung fortschrittlicher Analysetechniken. Nur so könne alle Arten von Statistiken aus den Daten extrahiert werden.
Andererseits können wir einen Schritt weiter gehen, indem wir Machine- und Deep-Learning-Modelle, wie z. B. Entscheidungsbäume oder sogar neuronale Netze, aus einem Trainingsdatensatz generieren und Vorhersagen auf einem Testsatz machen.
Die Genauigkeit der erstellten Modelle kann mit Hilfe von Scoring-Verfahren bewertet werden.
Es können Diagramme erstellt werden, die die erzielten Ergebnisse zeigen.
Die endgültigen Daten können zurück in eine Datenbank hochgeladen oder in CSV-Textdateien geschrieben werden.
Mit KNIME erstellte Entwicklungen können freigegeben werden, so dass sie von einem anderen Benutzer wiederverwendet werden können.
Sie können auch in Produktion gesetzt werden, d.h. der Fluss kann exportiert und automatisch periodisch ausgeführt werden So können wir eine Datenbank mit periodischen Ergebnissen füttern.
Wie wir sehen können, ist KNIME ein intuitives und einfaches Werkzeug mit einem riesigen Potenzial für seine einfache Integration und Skalierbarkeit. Mit seiner Einfachheit kann dennoch aus der Artikulation komplexer Datenflüsse, wertvolles Wissen extrahiert werden uvm. Kurz gesagt, Knime bedient die Fähigkeit, das Schwierige einfach zu machen.
Fazit
Zusammenfassend können wir sagen, dass die KNIME Analytics Platform ein Open Source und benutzerfreundliches Werkzeug ist. Mit KNIME wird die Entwicklung von Datentransformationsflüssen (ETL) auf einfache Weise ermöglicht, ohne die Notwendigkeit der Programmierung. In diesem Sinne ist eine der Hauptpotentiale, dass es eine Vielzahl von Knoten hat, mit denen man vom Laden und Transformieren von Daten bis hin zur Entwicklung von Machine Learning-Modellen und deren anschließendem Upload in ein Repository alles durchführen kann. Darüber hinaus ist es als Vorteil gegenüber Codezeilen möglich, den Zwischenstand der Daten zu überprüfen, während Transformationen durchgeführt werden, ohne dass diese Änderungen in der Datenbank wirksam werden, bevor sie in diese geschrieben werden.
 Kontakt
Kontakt