

Entwurf einer großen Datenarchitektur für die Produktionsdatenverarbeitung
Die perfekte Architektur für große Daten
Einer der größten Fortschritte des letzten Jahrzehnts war die Schaffung von Werkzeugen, die in der Lage sind, große Datenmengen zu verarbeiten. Anfang der 2000er Jahre begann Google mit der Untersuchung von Methoden zur verteilten Verarbeitung und Speicherung von Daten, was zu einem verteilten Dateisystem (GFS) und einer Verarbeitungsmethode namens MapReduce führte.
Von dort aus und dank der Innovation mehrerer Unternehmen, die ihre Methoden und Code-Repositorys der Gemeinschaft zur Verfügung stellten, wurden die Werkzeuge entwickelt, die es uns heute ermöglichen, riesige und vielfältige Datenquellen zu verarbeiten: „Big Data“.
Wenn wir von Großen Daten sprechen, beziehen wir uns auf massive Daten, die von Geräten oder individuellen Benutzeraktionen erzeugt werden können und die, wenn sie in Beziehung zueinander stehen, relevante Informationen über das Verhalten komplexer Systeme liefern.
Mit der Ankunft von IoT-Geräten, dem Internet der Dinge, ist es möglich, Daten von praktisch jeder Maschine wiederherzustellen. Im Logistik- und Produktionsbereich ist es möglich, Daten über die Maschinen, die industrielle Aufgaben ausführen, zu analysieren, um ihre Effizienz zu bestimmen, wenn sie ausfallen, oder um ihren Betrieb zu optimieren.
Ein effizienter Entwurf einer Big-Data-Architektur in einer produktiven Umgebung wäre in der Lage, die folgenden Funktionen zu erfüllen:
- Echtzeit-Datenverarbeitung zur Bestimmung der Effizienz von Industrieprozessen
- Mischen von chargengenerierten Daten (z. B. Daten aus einem ERP oder CRM) mit Echtzeitdaten für die Finanzanalyse
- Generierung von Dashboards, die sich aktualisieren, wenn Daten generiert und verarbeitet werden
- Analyse von Vorfällen, die die Erstellung von vorausschauenden Wartungsplänen aus den von IoT-Geräten
- erzeugten Daten ermöglichen Prozessoptimierung, wie z.B. Routenoptimierung oder Neuzuweisung von Ressourcen mit nahezu sofortigen Reaktionszeiten
- Analyse von Trends und Generierung von Empfehlungen aus den üblichen Operationen
Die perfekte Architektur für große Daten
So etwas wie eine perfekte, standardisierte Architektur gibt es nicht. Jedes Projekt, jeder Fall im Besonderen, bedingt die Merkmale der idealen Architektur. Um diese ideale Architektur zu erreichen, muss evaluiert werden, welche und wie viele Geräte diese Daten anbieten können oder durch Sensoren, die in der Lage sind, die für die Analyse erforderlichen Daten zu sammeln, in intelligente Geräte umgewandelt werden können. Aus diesen Daten wird in Abhängigkeit von der Häufigkeit der Datengenerierung und den notwendigen Korrelationen mit anderen Prozessen, wie z.B. Datenbanken mit Geschäftsinformationen, eine technologische Architektur geschaffen, die mit den Verarbeitungswerkzeugen von Big Data in der Lage sein kann, die relevanten Informationen für Geschäftsentscheidungen zu generieren, die Effizienz der Produktionsprozesse zu verbessern und mögliche Zwischenfälle, die die Produktionskapazität verringern können, vorherzusehen.
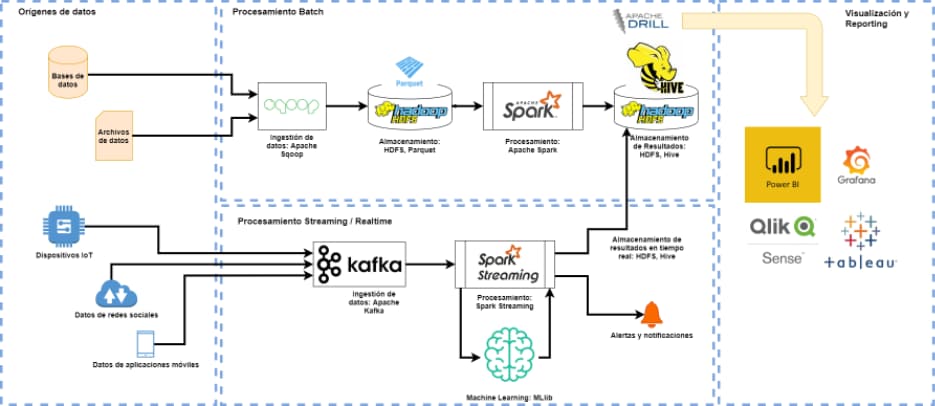
Bei LIS-Solutions arbeiten wir mit führenden Datenverarbeitungstechnologien wie Kafka und Spark aus der Apache Hadoop-Suite sowie mit Dashboard-Visualisierungstechnologien wie Qlik Sense, Power BI und Grafana. Diese Technologien haben es uns ermöglicht, Datenverarbeitungssysteme zu schaffen, die unseren Kunden relevante Informationen über ihre Produktionsprozesse liefern und es ihnen ermöglichen, den Betrieb ihres Unternehmens zu analysieren und zu optimieren.
 Kontakt
Kontakt